- Inicio
- Últimas noticias de poker
- La IA de GTO Wizard Derrotó a los LLM en Partidas Heads-Up de Póker
La IA de GTO Wizard Derrotó a los LLM en Partidas Heads-Up de Póker
GTO Wizard realizó un experimento para evaluar el desempeño de la IA moderna en el póker. Su agente jugó una serie de partidas cara a cara contra los principales modelos de lenguaje, desde GPT-5.4 hasta Kimi K2.5, y el resultado fue claro: todos los modelos fueron superados ampliamente.
5,000 manos sin ninguna posibilidad para los LLM
La IA se está expandiendo progresivamente en el uso cotidiano. Desde la búsqueda y la programación hasta el análisis avanzado, por lo que es apenas querer lógico evaluar su rendimiento en juegos con información incompleta, donde la estrategia, las matemáticas y la adaptación son esenciales.
Los primeros resultados, publicados a finales de 2025, demostraron que los modelos universales podían competir, pero aún estaban lejos de ofrecer un rendimiento consistentemente sólido. Recientemente, se llevó a cabo un nuevo experimento en el que los modelos de lenguaje ya no competían entre sí.
GTO Wizard* publicó los resultados de una prueba comparativa a gran escala: su IA especializada compitió contra todos los principales modelos de lenguaje. Los resultados fueron claros: la IA de GTO Wizard superó con creces a todos sus competidores.
*GTO Wizard es un equipo de desarrolladores que creó una plataforma de entrenamiento de póker basada en GTO y un solucionador en la nube.
Cómo se llevó a cabo la prueba comparativa de GTO Wizard
El experimento incluyó a todos los principales modelos: diversas versiones de GPT, Claude, Gemini, Grok y Kimi.
Cabe destacar que las condiciones fueron las mismas para todos los participantes:
- ♥️ Texas Hold'em sin límite.
- 💰 Stacks de 200 ciegas grandes.
- ⚔️ 5.000 manos jugadas en heads-up.
- 🤖 Una metodología de evaluación unificada que utiliza AIVAT, un sistema que reduce el impacto de la varianza aproximadamente diez veces y mide la calidad de las decisiones desde una perspectiva de GTO, en lugar de basarse en los resultados brutos de la mesa.
Un detalle clave: los desarrolladores no aclararon si el rake se tuvo en cuenta en los resultados. Sin embargo, incluso al calcularlo con un rake del 5%, el resultado general del partido se mantuvo sin cambios.
Resultados: Ruptura total
El resultado fue claro: todos los modelos perdieron y bastante.
- GPT-5.3 XHigh Reasoning mostró el mejor resultado: -16 bb/100. Para contextualizar, los profesionales expertos en partidas heads-up contra otros jugadores mantienen un nivel de aproximadamente +4 bb/100 (este es el punto de referencia utilizado por GTO Wizard).
- GPT-5.4 Nano (sin razonamiento) mostró los peores resultados: -189,7 bb/100.
| Posición | Modelo | Desarrollador | Tasa de victoria ajustada por suerte (bb/100) | Desviación estándar |
|---|---|---|---|---|
| 1 | GPT-5.3 (XHigh Reasoning) | OpenAI | -16.0 | ±3.0 |
| 2 | Marvel | MIT | -14.0 | ±4.7 |
| 3 | GPT-5.4 (XHigh Reasoning) | OpenAI | -17.8 | ±3.7 |
| 4 | GPT-5.3 (High Reasoning) | OpenAI | -18.2 | ±3.9 |
| 5 | Claude Opus 4.6 | Anthropic | -20.4 | ±4.4 |
| 6 | Gemini 3.1 Pro | ~-30.8 | — | |
| 7 | Kimi K2.5 | Moonshot AI | ~-40 a -50 | — |
| 8 | Grok 4 | xAI | ~-60 | — |
| 9 | GPT-4o / líneas base anteriores | OpenAI | < -100 | — |
| 10 | GPT-5.4 Nano (sin razonamiento) | OpenAI | -189.7 | — |
¿Por qué perdieron los LLM?
Tras analizar las manos, el equipo de GTO Wizard identificó cuatro factores sistémicos que impiden que los modelos universales jueguen al póker a un alto nivel:
- 🕶️ Información oculta: el modelo no puede ver las cartas del oponente y debe basarse completamente en probabilidades.
- ⚖️ Equilibrio de rangos: el póker presenta miles de situaciones donde incluso pequeños desequilibrios estratégicos pueden ser explotados.
- 🧠 Planificación a largo plazo: cada decisión afecta a las siguientes rondas, y los errores se acumulan, generando pérdidas de valor esperado (EV).
- ❓ Modelado del comportamiento del oponente en condiciones de incertidumbre: esto requiere un modelo probabilístico robusto, que los LLM no proporcionan explícitamente.
También se identificó un problema fundamental: incluso los modelos avanzados malinterpretan sus propias cartas en aproximadamente el 2% de los casos, confundiendo palos y combinaciones. En el póker, estos errores se traducen instantáneamente en un EV negativo.
¿Cuál es la fortaleza de la IA de GTO Wizard?
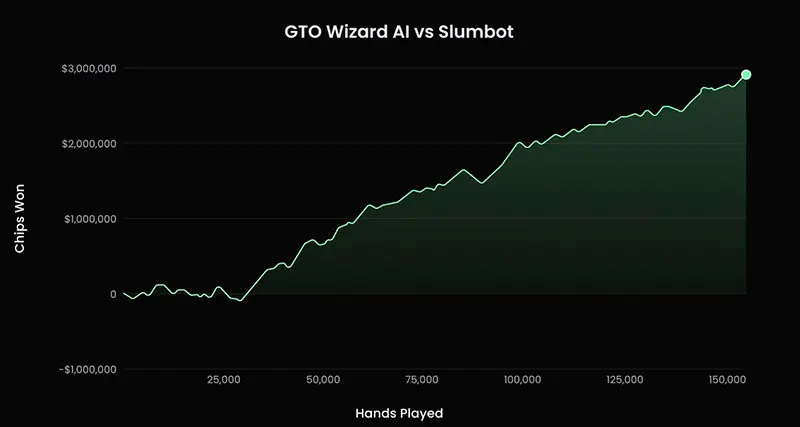
Los desarrolladores destacan que la IA de GTO Wizard juega cerca del equilibrio de Nash, lo que la hace altamente resistente a la explotación.
El punto de referencia que utilizan es de alrededor de 4 bb/100 como el nivel de los jugadores de élite frente al resto. Sin embargo, según la lógica del modelo, incluso los jugadores de este nivel perderían contra una IA especializada.
La base técnica del sistema es Ruse AI, desarrollada por los investigadores canadienses Philippe Birdsell y Marc-Antoine Provost. En 2023, venció a Slumbot, uno de los bots de póker públicos más potentes, con una puntuación de +19,4 bb/100 en más de 150.000 manos. Posteriormente, el proyecto se integró en el ecosistema de GTO Wizard y se convirtió en la base del motor de IA actual.
El formato del experimento también merece ser destacado. GTO Wizard ha hecho público el benchmark: cualquier desarrollador puede conectar su agente a través de la API y jugar las mismas partidas heads-up. Esto convierte al sistema en un estándar único para evaluar la IA de póker y permite comparaciones directas entre diferentes modelos en las mismas condiciones.
GTO Wizard vs. LLM: Conclusión principal
Los resultados del experimento son inequívocos: los modelos de lenguaje generales aún no pueden competir con los agentes de póker especializados, ni siquiera en partidas heads-up.
La brecha entre ambos enfoques resultó ser sistémica, no fortuita. Demuestra claramente las limitaciones actuales de las capacidades: inteligencia de propósito general frente a optimización altamente especializada.
En este contexto, el póker no es solo un juego, sino una prueba de fuego para evaluar las capacidades y los límites de los sistemas modernos de aprendizaje automático.
La Serie Mundial de Póker 2026 empezó en Las Vegas el 26 de mayo. Aquí encon...
Para sus retransmisiones de la WSOP, ESPN estrena un nuevo software de IA desarrollado por Luke G...
Alberta se ha convertido en la segunda provincia canadiense, después de Ontario, en lanzar...
Apenas una semana después de que su selección, Brasil, fuera eliminada del Mundial ...